




Dlaczego architektura ma znaczenie? Architektura aplikacji definiuje jej poszczególne komponenty, pełnione przez nie funkcje, a także panujące między nimi relacje. Zapewnia jasny podział odpowiedzialności oraz niskie sprzężenie elementów, co z kolei przekłada się na łatwość utrzymania, dobrą skalowalność oraz możliwość ponownego wykorzystania kodu. Wspomniane korzyści dotyczą zarówno małych jak i dużych rozwiązań i są niezależne od stosowanej technologii. Decyzja, jakiej architektury użyć jest niezwykle istotna, a jej zmiana w późniejszym czasie bardzo kosztowna. Dlatego osoby odpowiedzialne za jej planowanie powinny posiadać szeroką wiedzę z zakresu wykorzystywanych technologii, narzędzi oraz powszechnie przyjętych praktyk i standardów.
Złożoność aplikacji Android
Każdy, kto chociaż raz pisał aplikację na platformie Android, wie, że nie jest to zadanie trywialne. Istnieje wiele niebiznesowych aspektów, które należy uwzględnić podczas tego procesu np. duża fragmentacja dostępnych urządzeń, konieczność zachowania kompatybilności wstecznej, złożoność API, różnorodność komponentów, efektywne gospodarowanie zasobami, zarządzanie stanem i jego synchronizacja, wielowątkowość oraz wiele innych. To wszystko sprawia, że dostarczenie prostej aplikacji wymaga szerokiej wiedzy, a także stosunkowo dużego nakładu pracy. Innym aspektem, który należy poruszyć, jest sam zakres funkcjonalny. Początkowo aplikacje mobilne realizowały zwykle jedno, bardzo dobrze określone zadanie np. pokazywały aktualną pogodę. Obecnie są one mocno rozbudowane i często przypominają aplikacje znane z platform desktopowych. Te czynniki wymuszają konieczność stosowania architektury, która pozwoli zapanować nad złożonością i da jasny obraz tego co dzieje się w aplikacji.
Architektura aplikacji Android
Coraz większa liczba programistów zdaje sobie sprawę, jak bardzo istotne jest stosowanie architektury. Jednak oficjalna dokumentacja nie narzuca konkretnego rozwiązania --- brakuje wskazówek i wzorców. Szukając informacji w sieci można wskazać trzy bardzo popularne podejścia --- "klasyczne", MVP oraz MVVM. Często są one realizowane z udziałem dodatkowych bibliotek np. Dagger (Dependency Injection), Otto (Event bus), ButterKnife (bindowanie elementów widoku).
Architektura "klasycznie"
W podejściu tym bardzo często cała logika aplikacji zaszyta jest w klasach aktywności i fragmentów, które w efekcie stają się przeładowane odpowiedzialnością. Występuje silne powiązanie między warstwą widoku i resztą kodu co z kolei bardzo utrudnia wprowadzanie zmian oraz dalszy rozwój aplikacji. Innym negatywnym skutkiem jest brak możliwości ponownego użycia kodu, a także tworzenia testów. Całość aplikacji jest trudna nie tylko w utrzymaniu, ale także w zrozumieniu. Ponadto z uwagi na to, że bardzo często mamy do czynienia z kodem asynchronicznym aplikacja staje się jeszcze bardziej złożona (wielokrotnie zagnieżdżone funkcje typu callback)
W nieco lepszym wariancie całość aplikacji zostaje podzielona na dwie warstwy:
- Model --- realizuje logikę aplikacji np. dostęp do bazy, wykorzystanie Rest API,
- View --- prezentuje informacje, odpowiada za interakcje z użytkownikiem.
Idealnie warstwa modelu powinna być realizowana z wykorzystaniem klas typu Service, jednak w praktyce nie jest to często spotykany przypadek.
Architektura Model View Presenter (MVP)
MVP jest pochodną wzorca Model View Controller. Zasadnicza różnica między nimi polega na sposobie komunikacji między komponentami.

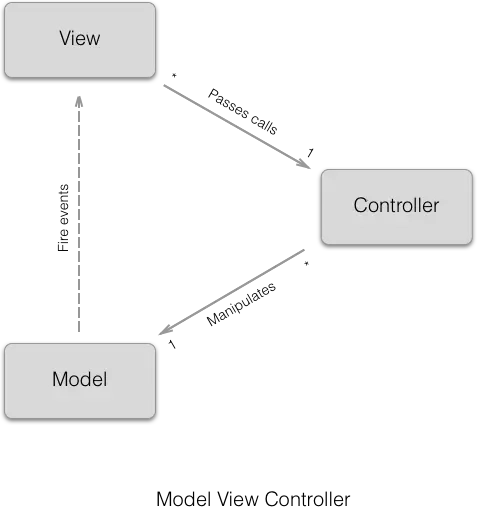
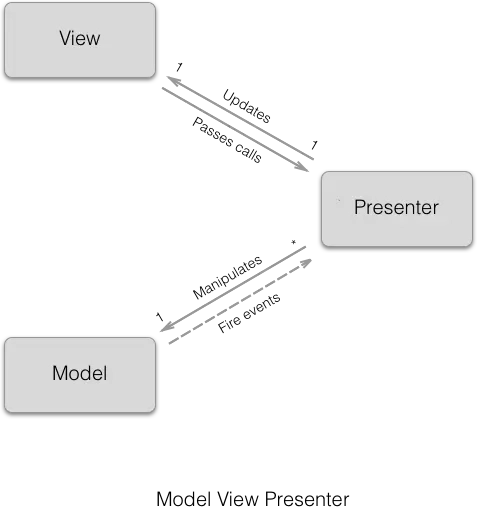
Całość aplikacji dzielona jest na trzy warstwy:
- Model --- reprezentuję domenę problemu i realizuje logikę biznesową,
- Presenter --- działa zarówno na poziomie modelu jak i widoku --- odpowiada za wykonanie logiki oraz skonfigurowanie stanu widoku,
- View --- pasywnie prezentuje dane, przekazuje informacje o zachodzących zdarzeniach do prezentera.
Warto zauważyć, że sam prezenter powinien być całkowicie oderwany od technologii widoku. Takie podejście zapewnia możliwość wykonywania testów jednostkowych na poziomie modelu, jak i prezentera bez konieczności uruchamiania aplikacji na symulatorze czy fizycznym urządzaniu. Dodatkowo, jeśli zajdzie potrzeba zmiany klasy prezentującej widok np. z aktywności na fragment nie ma konieczności modyfikowania pozostałych warstw.
Architektura Model View ViewModel (MVVM)
Model View ViewModel staje się coraz bardziej popularny nie tylko na platformie Android. Bardzo często realizuje się go z wykorzystaniem bibliotek bindujących umożliwiających automatyczną synchronizację danych z widokiem i odwrotnie (od niedawna dostępne natywnie na Android).
Całość aplikacji dzielona jest na trzy warstwy:
- Model --- reprezentuje domenę problemu i realizuje logikę biznesową,
- ViewModel --- udostępnia model danych przygotowanych pod konkretny widok, realizuje logikę związaną z prezentacją,
- View --- definiuje strukturę i rozkład elementów widoku.

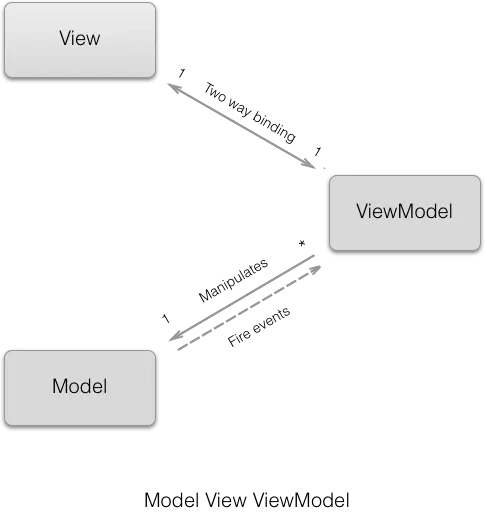
Klasy ViewModel nie powinny zawierać kodu związanego z samym widokiem --- odpowiadają wyłącznie za dostarczanie modelu danych, np. odpowiednio sformatowanej daty, czy listy użytkowników. Główna zmiana w stosunku do MVP polega na sposobie komunikacji --- widok obserwuje model i w momencie zmiany jego stanu automatycznie się odświeża (możliwe jest także bindowanie dwukierunkowe). Korzyści płynące z takiego podejścia pokrywają się z tymi, które wymienione zostały w przypadku wzorca MVP, jednak dzięki bindowaniu programista nie musi pisać powtarzającego się kodu, który odpowiadałby za przeniesienie stanu z modelu na widok i odwrotnie.
Realizując MVVM można skorzystać z dowolnej biblioteki bindującej, jednak warto wspomnieć o rozwiązaniu RxAndroid. Jest to implementacja biblioteki Reactive Extensions umożliwiającej tworzenie aplikacji w stylu funkcyjno-reaktywnym. Można powiedzieć, że to swojego rodzaju rozszerzenie koncepcji wzorca obserwatora --- obserwujemy sekwencje zdarzeń (kliknięcie myszką, nowe dane z serwera, zmiana statusu itp.), a poprzez specjalne funkcje operatorów strumienie takie można modyfikować np. mapować, filtrować lub kombinować. Dzięki temu wszystko co dzieje się w aplikacji jest konsekwencją reakcji na zdarzenie i nie ma konieczności bezpośredniego przechowywania stanu. Bardzo często pozwala to na uniknięcie sporej ilości logiki związanej np. z warunkowym prezentowaniem informacji w zależności od aktualnego stanu. Warto dodać, że w odróżnieniu od wzorca obserwatora, publikujący może rozgłosić dwa dodatkowe typy zdarzeń --- informujące o błędzie lub o tym, że sekwencja się skończyła.
Wszystkie omawiane podejścia zostały pokazane na przykładzie prostej aplikacji wyświetlającej repozytoria github. Są one dostępne na moim githubie (każda architektura to osobny branch).





