




Od czego zależy sukces w grze Eurobiznes? Z tego, co pamiętam, gdy kilkanaście lat temu grywałem w tę grę dość często, głównie od talentu negocjacyjnego. Jeśli zdarzy ci się jeszcze, czytelniku, w tę zagrać, niniejszy artykuł może wzmocnić twoją pozycję negocjacyjną. Spróbujemy policzyć, z jakim prawdopodobieństwem gracze zatrzymują się na każdym z pól, co jest ważnym czynnikiem wpływającym na wartość kupowanych nieruchomości.
Do oszacowania tych prawdopodobieństw użyjemy metody Monte Carlo. W artykule postaram się pokazać:
- na czym polega metoda Monte Carlo i dlaczego jest piękna,
- jak ją zaprogramować w R,
- jak sprawdzić, czy wyniki mają sens,
- jak ocenić, czy liczba symulacji jest wystarczająca.
Najpierw przypomnijmy sobie, jak wygląda plansza do gry Eurobiznes (rys. 1). Składa się ona z 40 pól numerowanych od 1 (pole "Start") do 40 ("Wiedeń"). Mamy jedno pole, które zmienia położenie (31, "Idziesz do więzienia") i sześć, które potencjalnie zmieniają położenie (karty szans: 16 niebieskich i 16 czerwonych). Będziemy je dalej nazywać polami specjalnymi. Oprócz tego, jeśli w wyniku rzutu kostkami otrzymamy na obu taką samą liczbę oczek, rzucamy jeszcze raz, przemieszczając się o tyle pól, ile w sumie wypadło oczek w obu rzutach. Jeśli jednak ponownie coś takiego się wydarzy, idziemy do więzienia, czyli na pole 11.


Jak policzyć prawdopodobieństwa zatrzymania się na poszczególnych polach? Możemy rzucać kostką i zapisywać, gdzie stanęliśmy. Jeśli się uprzemy i zrobimy to naprawdę dużo razy, szukane prawdopodobieństwo otrzymamy, dzieląc liczbę przypadków zatrzymania się na danym polu przez liczbę wszystkich rzutów. To jest istota metody Monte Carlo. Chodzi tylko o to, by zamiast samemu rzucać kostką, zmusić do tego komputer.
Napiszmy pseudokod, który coś takiego zrealizuje. Dla prostoty będziemy grali sami ze sobą, gdyż interakcje między graczami i tak nie zmieniają położenia.
1# ustaw się na polu start 2# powtarzaj N razy: 3# rzuć dwiema kostkami 4# jeśli liczba oczek nie jest taka sama, przesuń się o sumę oczek 5# w przeciwnym wypadku rzuć jeszcze raz 6# jeśli liczba oczek nie jest taka sama, przesuń się o sumę oczek z obu rzutów 7# w przeciwnym wypadku idziesz do więzienia 8# jeśli trafiłeś na pole specjalne, zmień pozycje 9# zapamiętaj, w jakim polu się znalazłeś
Zacznijmy od uproszczonej wersji, która nie będzie uwzględniać pól specjalnych. Pamiętajmy, że chodzimy w kółko, także po polu 40 następuje pole 1, a nie 41 (dlatego będziemy dzielić modulo 40). Trzeba jeszcze uważać, gdyż 40 %% 40 = 0, zatem pozycję 0 należy zmienić na 40. W poniższym kodzie tworzymy 40-elementowy wektor wypełniony zerami i jeśli staniemy na przykład na polu 10, zwiększymy o jeden 10. element tego wektora. Uwaga, poniższy kod nie jest napisany optymalnie (to znaczy tak, by całość wykonała się jak najszybciej), ale nacisk został położony na czytelność.
1N <- 1e6 # liczba symulacji 2pola <- numeric(40) # tu zapiszemy, jak często stanęliśmy na danym polu 3pozycja <- 1 # początkowa pozycja (start) 4pola[1] <- 1 5for (i in 1:N) { 6 rzut1 <- sample(1:6, 2, replace = TRUE) 7 if (rzut1[1] != rzut1[2]) { 8 pozycja <- pozycja + sum(rzut1) 9 } else { 10 rzut2 <- sample(1:6, 2, replace = TRUE) 11 if (rzut2[1] != rzut2[2]) { 12 pozycja <- pozycja + sum(rzut1) + sum(rzut2) 13 } else { 14 pozycja <- 11 # idziesz do więzienia 15 } 16 } 17 pozycja <- pozycja %% 40 18 if (pozycja == 0) pozycja <- 40 # uwaga na 40 %% 40 19 pola[pozycja] <- pola[pozycja] + 1 20} 21names(pola) <- 1:40 22barplot(pola / N, col = "cadetblue", 23 las = 1, cex.axis = 0.8, cex.names = 0.8)

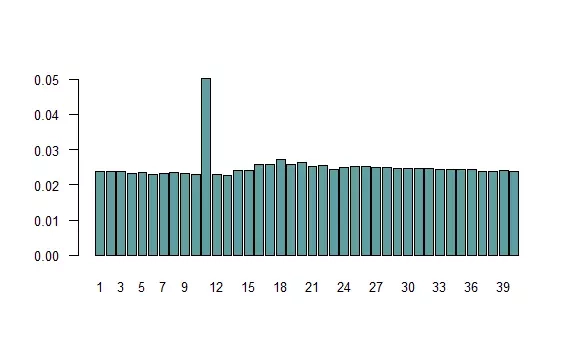
Na powyższym wykresie zaprezentowano częstości pojawień się na poszczególnych polach. Zastanówmy się, czy są one sensowne. Gdyby powtórzone wyrzucenie tej samej liczby oczek nie skutkowało pójściem do więzienia (pole 11), rozkład powinien być jednostajny. Prawdopodobieństwo takiego wydarzenia jest niewielkie, więc obserwowany rozkład (poza więzieniem) rzeczywiście przypomina jednostajny. Ponieważ pole 11 jest odwiedzane częściej od pozostałych, stąd też pola odległe o około 7 oczek (najbardziej prawdopodobna suma dwóch rzutów) są trochę popularniejsze. Czy to, że więzienie odwiedzamy około dwa razy częściej, da się wyjaśnić? Policzmy. Prawdopodobieństwo wyrzucenia tego samego na obu kostkach wynosi $$1\over6$$, w takim razie z prawdopodobieństwem $$1\over36$$ stanie się to dwa razy z rzędu. Z kolei prawdopodobieństwo stanięcia na dowolnym polu wynosi $$1\over40$$, czyli dla więzienia $$\frac{1}{36} + \frac{1}{40}$$, więc ponad dwa razy więcej. Jest to przybliżony wynik, gdyż podając wartość $$1\over4$$, założyłem brak więzienia.
Uwzględnijmy teraz pola specjalne. Mamy pole 31, z którego zawsze idziemy do więzienia, oprócz tego w polach 3, 18 i 34 bierzemy niebieską kartę szansy, natomiast w polach 8, 23 i 37 czerwoną kartę szansy. Wśród niebieskich kart istnieją trzy zmieniające położenie: "Wracasz na start" (1), "Idziesz do więzienia" (11), "Idziesz do Wiednia" (40). Wśród czerwonych kart mamy siedem zmieniających położenie: "Wracasz na start" (1), "Idziesz do Neapolu" (7), "Idziesz do więzienia" (11), "Wracasz do Madrytu" (15), "Wracasz do Brukseli" (24), "Idziesz do Kolei Wschodnich" (36), "Cofasz się o trzy pola". Możemy zatem założyć, że jeśli trafimy na pole z niebieską kartą, z prawdopodobieństwem $$13\over16$$ nie zmienimy położenia, natomiast z prawdopodobieństwem $$1\over16$$ przesuniemy się na pole 1, 11 lub 40. Podobnie w przypadku czerwonej karty: z prawdopodobieństwem $$9\over16$$ nie zmienimy położenia, z prawdopodobieństwem $$1\over16$$ przesuniemy się na pole 1, 7, 11, 15, 24, 36 lub cofniemy się o trzy pola. Napiszmy funkcję realizującą zmianę położenia (uwzględnimy w niej również dzielenie modulo).
1zmien_pozycje <- function(p) { 2 p <- p %% 40 3 if (p == 0) { 4 p <- 40 5 } else if (p == 31) { # idziesz do więzienia 6 p <- 11 7 } else if (p %in% c(3, 18, 34)) { # niebieska karta 8 # z pewnym prawdop. zostań na polu albo zmień pozycje: 9 p <- sample(c(p, 1, 11, 40), 1, prob = c(13/16, 1/16, 1/16, 1/16)) 10 } else if (p %in% c(8, 23, 37)) { # czerwona karta 11 p <- sample(c(p, 1, 7, 11, 15, 24, 36, p-3), 1, prob = c(9/16, rep(1/16, 7))) 12 } 13 return(p) 14} 15 16N <- 1e6 17pola <- numeric(40) 18pozycja <- 1 19pola[1] <- 1 20for (i in 1:N) { 21 rzut1 <- sample(1:6, 2, replace = TRUE) 22 if (rzut1[1] != rzut1[2]) { 23 pozycja <- pozycja + sum(rzut1) 24 } else { 25 rzut2 <- sample(1:6, 2, replace = TRUE) 26 if (rzut2[1] != rzut2[2]) { 27 pozycja <- pozycja + sum(rzut1) + sum(rzut2) 28 } else { 29 pozycja <- 11 30 } 31 } 32 pozycja <- zmien_pozycje(pozycja) 33 pola[pozycja] <- pola[pozycja] + 1 34} 35barplot(pola / N, col = "cadetblue", names.arg = 1:40, 36 las = 1, cex.axis = 0.8, cex.names = 0.8)
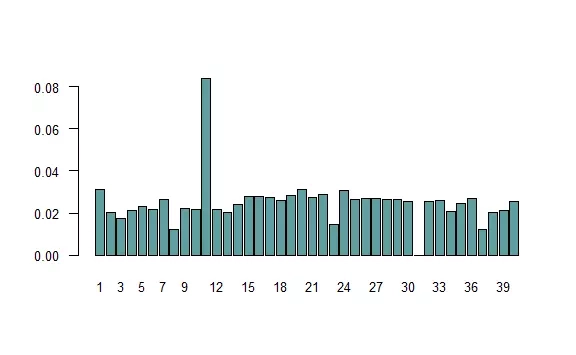
Rozkład zmienił się wyraźnie. Jest znacznie większe ryzyko, że pójdziemy do więzienia, na niektórych polach zatrzymamy się rzadziej. Częściowo wynika to z przyjętej konwencji: ani razu nie zatrzymujemy się na polu 31, gdyż natychmiast idziemy do więzienia. Podobnie pola z czerwoną kartą są rzadkie, bo jest duża szansa, że zaraz je opuścimy. Pola te nie są jednak dla nas interesujące, gdyż nie możemy ich kupić.
Ktoś mógłby mieć uzasadnione wątpliwości, czy ta cała procedura zwraca poprawne wyniki? Jaką mamy pewność, że to, co otrzymaliśmy, to prawdziwe prawdopodobieństwa? Wynika to z tak zwanego Prawa Wielkich Liczb. Na poszczególne proporcje (pola/N) możemy spojrzeć jak na średnią arytmetyczną $$\frac{x_1+\ldots+x_N}{N}$$, gdzie $$x_i$$ są równe 1, gdy w $$i$$-tym ruchu zatrzymaliśmy się na danym polu, oraz 0, gdy nie. Nie wnikając w szczegóły, Prawo Wielkich Liczb mówi, że wraz ze zwiększającym się $$N$$, taka średnia arytmetyczna dąży do "prawidłowej" wartości (wartości oczekiwanej, w tym przypadku proporcji). Ktoś jeszcze bardziej dociekliwy mógłby jednak zadać pytanie, czy zaobserwowane różnice w częstości nie są przypadkowe? Czy milion symulacji to wystarczająco dużo? Tu z kolei można wykorzystać inne, jeszcze większe twierdzenie statystyki matematycznej, Centralne Twierdzenie Graniczne. My jednak użyjemy znacznie prostszej metody: po prostu uruchommy całość jeszcze raz (ewentualnie kilka razy). Okaże się, że dostaniemy praktycznie identyczny wykres, a w takim razie nie ma sensu zwiększać liczby symulacji.
Na koniec zastanówmy się, czy te symulacje były potrzebne? Skoro całość zależy od wyników rzutu kostką i wylosowania ze znanym prawdopodobieństwem odpowiednich kart, w takim razie problem powinien być rozwiązywalny analitycznie. Sytuacja jest jednak tak skomplikowana, że byłoby to ekstremalnie trudne. Wyobraźmy sobie jednak, że znalazł się ktoś odważny. Zadajmy sobie pytanie, jaka jest szansa, że nie popełnił choć jednego błędu? I w ten sposób dochodzimy do ważnego powodu korzystania z metody Monte Carlo, którego być może nie każdy jest świadom. Nawet jeśli rozwiązanie analityczne jest na horyzoncie, to metoda Monte Carlo jest zwykle bezpieczniejsza, to znaczy mniej podatna na błędy. Doceńmy na koniec, jak proste, a przez to piękne jest to podejście: po prostu rzucamy wielokrotnie kostką i zapisujemy wyniki.





