




Data Scientist - inaczej Data Science specialist, czyli kto? W skrócie Data Scientist to osoba zajmująca się m.in. zbieraniem, przetwarzaniem, analizą i wizualizacją danych przy użyciu uczenia maszynowego i algorytmów uczących się. Data Scientist to w bardzo dużym uproszczeniu połączenie zawodów Data Engineer i Data Analyst. Data Science specialist musi posiadać umiejętności i kompetencje z wielu różnych dziedzin. Powinien umieć programować, znać technologie big data i analizę danych a dodatkowo posiadać umiejętności komunikacyjne oraz rozumieć biznes. Dlaczego? Szczegółowo wyjaśniamy to w poniższym artykule.
Kim właściwie jest Data Scientist?
Czy Data Scientist to najnowszy buzzword, czy za tym terminem faktycznie kryje się jakieś nowe znaczenie? Z wielu źródeł słyszymy, że to zawód przyszłości, najbardziej pożądana rola w IT, a jednocześnie ciekawa ścieżka kariery, pełna wyzwań i ciekawych problemów do rozwiązania.
Do zapotrzebowania na statystyków, specjalistów w dziedzinie analizy danych i uczenia maszynowego, a także programistów zdążyliśmy się już przyzwyczaić. Trendem ostatnich lat jest natomiast zbliżanie się do siebie tych, odseparowanych dotychczas ról. W kontekście przetwarzania dużych ilości danych (big data) trudno obecnie zajmować się na przykład uczeniem maszynowym, w oderwaniu od kwestii wydajnościowych i planowania wdrożenia produkcyjnego opracowanych rozwiązań. Biznes oczekuje realnej wartości, w postaci przekazanych w przekonywujący sposób wniosków i predykcji lub działających produkcyjnie rozwiązań, a nie hermetycznych analiz, zrozumiałych tylko dla ekspertów z danej dziedziny.
W związku z powyższym wydaje się, że za pomocą terminu Data Scientist udało się raczej uwypuklić oczekiwanie połączenia w jednej roli cech, które do tej pory rozproszone były wśród specjalistów z różnych obszarów, niż zidentyfikować jakąś zupełnie nową rolę.
Czy to oczekiwanie jest realne do spełnienia? Czy jedna osoba może faktycznie być zarówno świetnym programistą, statystykiem rozpraszającym algorytmy na klastrze, osobą dokładnie rozumiejącą biznes, w ramach którego działa firma, a jednocześnie posiadać wysokie kompetencje komunikacyjne i umieć przekazywać swoje wnioski i przewidywania w postaci pięknych infografik i wykresów?
To niewątpliwie duże wyzwanie dla działów rekrutacji, stąd wiele na wpół ironicznych porównań poszukiwania Data Scientists do poszukiwania jednorożca. Można przyjąć, że opisany wyżej profil do pewien niedościgniony wzorzec, idealny pracownik nowoczesnej firmy, który jest w stanie wykroczyć poza granice utartych działów w firmie i wykorzystać głęboką wiedzę merytoryczną do przekształcenia dostępnych dla firmy danych w realną korzyść.
W pewnych sytuacjach tego rodzaju specjalista staje się kierownikiem projektu, który nawet jeśli bezpośrednio nie angażuje się w tak różne pola działania, musi zarządzać zespołem i współpracować z wieloma zaangażowanymi stronami. Staje się wówczas łącznikiem pomiędzy ekspertami w zakresie analizy danych i programistami, a ekspertami dziedzinowymi i zarządem.
Data Scientist po polsku – problemy z tłumaczeniem
Z terminem Data Scientist jest w problem w języku polskim — jak to przetłumaczyć? Nie da się niestety literalnie, analityk danych nie oddaje pełnego znaczenia tej roli, lansowany przez Wikipedię mistrz danych brzmi dosyć dziwnie i obco, niektórzy próbują z badaczem danych. W tej wersji tracimy z kolei związek z nazwą dziedziny — Data Science — która w oryginalne wyraźnie sugeruje, że mamy tu do czynienia wręcz z osobną dyscypliną. Generalnie dziedzina analizy danych i uczenia maszynowego ma pecha, jeśli chodzi o terminologię w języku polskim, np. zgrabne data mining nie daje się po polsku równie płynnie wypowiedzieć jako kopanie danych, najsensowniejsze jest nieco odleglejsze eksploracja danych. Z braku lepszych opcji pozostańmy więc przy oryginalnym Data Scientist.
Próbę omówienia zagadnienia tłumaczenia Data Science po polsku podjął Norbert Ryciak w artykule: Danetyka, czyli o polskim tłumaczeniu Data Science
Data Scientist umiejętności i wymagania
W pracy w Data Science istotne jest posiadanie licznych kompetencji z wielu różnych specjalności. Pożądane na rynku pracy jest to, aby Data Scientist miał zdolności matematyczne i analityczne, umiał programować, potrafił zaprezentować analizowane dane i wyciągnąć konkretne wnioski. Dodatkowo taka osoba powinna cechować się dociekliwością, umiejętnością opowiadania historii przez dane (data storytelling) i rozumieć potrzeby biznesu. Szczegółowo zostało to przedstawione na poniższej grafice.

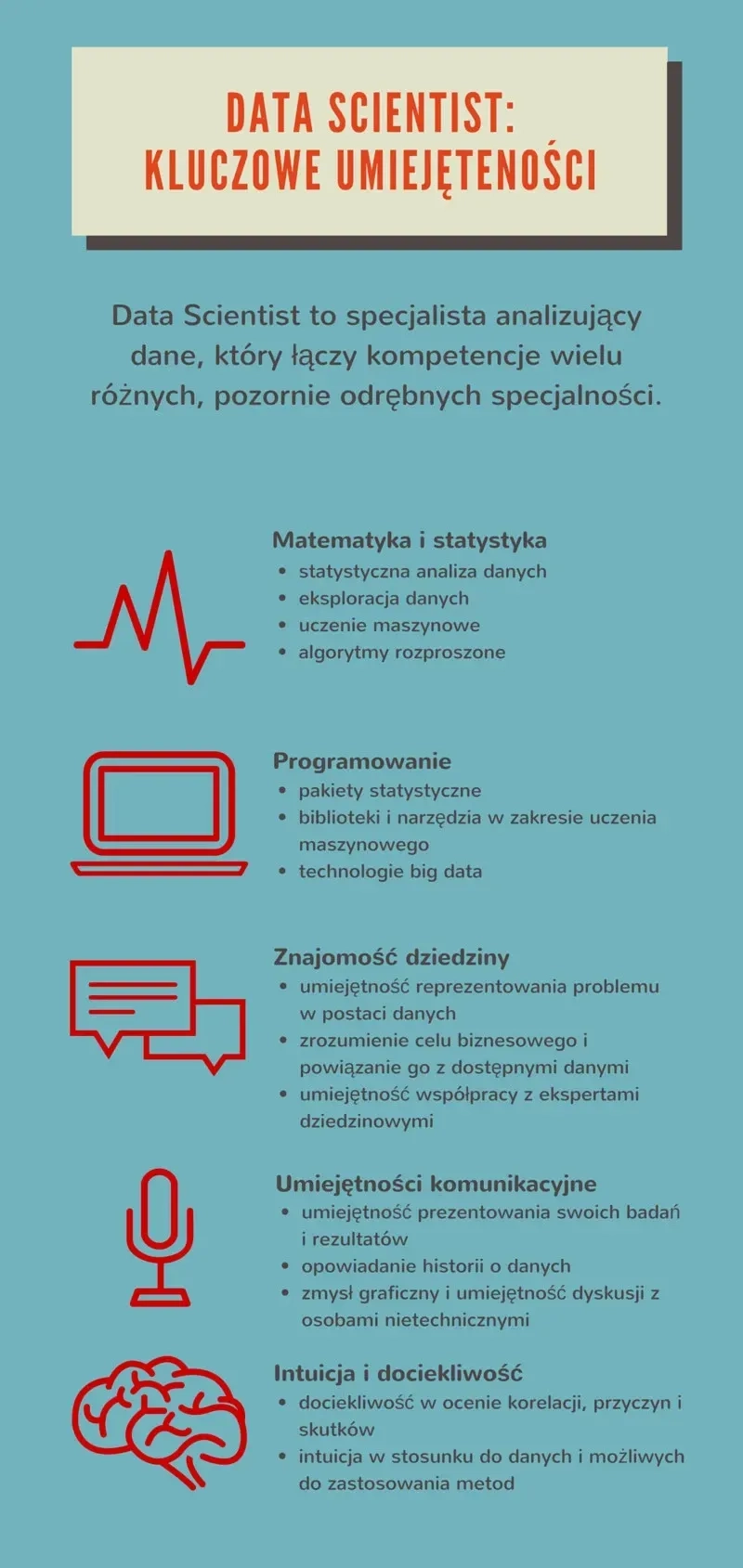
Data Scientist: pożądane cechy. Czy szukamy jednorożca?
Dlaczego właśnie teraz wszyscy poszukują Data Scientists?
Powstaje pytanie dlaczego właśnie teraz --- w ciągu ostatnich kilku lat --- nastąpiło tego rodzaju przesunięcie w stosunku do oczekiwań wobec pracowników? Po pierwsze jest to wspomniany już wpływ trendu big data i konieczności zajmowania się na tyle dużymi wolumenami danych, że kwestie implementacyjno-techniczne stają się istotne już na wczesnym etapie przetwarzania danych.
Po drugie, jest to też uświadomienie sobie przez firmy, że w zasadzie w każdym biznesie zbieranie, analizowanie i przetwarzanie danych niesie ze sobą potencjalnie dużą wartość. Im więcej firm wykorzystuje tego rodzaju działania do zwiększenia swojej przewagi konkurencyjnej, tym bardziej napędza to ogólny wyścig, w którym nikt nie chce zostać w ogonie.
Po trzecie, przetwarzanie danych staje się coraz dostępniejsze, zarówno ze względu na mnogość platform, narzędzi i bibliotek służących temu celowi, jak i pewne osiągnięcia w samej dziedzinie uczenia maszynowego. Mowa tutaj o głębokim uczeniu sieci neuronowych (deep learning), grupie metod, które spowodowały, że nagle w wielu zastosowaniach efekty osiągane dotychczas mozolną pracą eksperymentalną (dobieranie metod i cech do danego problemu), możliwe są obecnie praktycznie od ręki.
Spójrzmy na trendy wyszukiwania poniżej. Uczenie maszynowe (kolor zielony) to hasło, które raczej traciło na popularności do 2011 roku. To okres rozczarowania tym, że mimo wielu lat rozwoju tej dziedziny wciąż nie żyjemy w świecie z książek science fiction, lata świetlne dzielą nas od prawdziwej sztucznej inteligencji, a systemy funkcjonujące obecnie szybko okazują się bardzo ograniczone lub wręcz nieprzydatne, wbrew marketingowym obietnicom.


Trendy wyszukiwania hasła Data Scientist i powiązanych
Rok 2011 to też początek hype'u terminu big data, zachłyśnięcie się pomysłem, że można i warto zbierać wszystkie dane, jakie tylko są pod ręką, ponieważ po wpuszczeniu ich w odpowiednią maszynkę obliczeniową uzyskamy kluczową wiedzę, która do tej pory była dla nas niedostępna. Okres rozczarowania tą koncepcją rozpoczął się zupełnie niedawno.
Ciekawą korelację można zaobserwować między popularnością hasła "deep learning" (kolor żółty) i "data science" (kolor niebieski). Zbieżność czasowa wydaje się potwierdzać hipotezę, że możliwość stosowania tej grupy metod uczenia maszynowego wzmacnia trend poszukiwania osób posiadających kompetencje z tego zakresu i jednocześnie umiejących wykorzystać je do dostarczenia wartości dla firmy.
Czym zajmują się Data Scientists?
W tej chwili zapewne należałoby zapytać: w jakich obszarach jeszcze nie pracują Data Scientists? Z analizą danych mamy tak naprawdę do czynienia w każdej dziedzinie i branży, można jedynie powiedzieć, gdzie jest to kluczowe lub najbardziej obiecujące.
W branży finansowej kluczowe jest analizowanie danych o transakcjach bankowych i wspomaganie decyzji kredytowych, np. wykrywanie nadużyć (fraud detection), które umożliwia zidentyfikowanie najbardziej podejrzanych operacji i przekazanie ich do dalszej analizy przez człowieka.
W marketingu bardzo wartościowe okazuje się analizowanie zachowania użytkowników na stronach internetowych, np. sklepów online. Pozwala to między innymi na tworzenie coraz doskonalszych systemów rekomendacyjnych, wskazujących klientowi produkty, które z dużym prawdopodobieństwem jest skłonny kupić, nawet jeśli ich aktywnie nie szuka.
Innym ciekawym obszarem pracy Data Scientist jest śledzenie widoczności i opinii o marce w Internecie przez zastosowanie rozwiązań z zakresu przetwarzania języka naturalnego. Szczególnie dla marek globalnych istotne jest monitorowanie i reagowanie na zmianę postrzegania firmy, wyrażoną wypowiedziami w Internecie, np. w recenzjach produktów, czy po prostu w dyskusjach w sieciach społecznościowych. Bez analiz automatycznych byłoby to wręcz niemożliwe, ze względu na wolumen danych lub ograniczone do niewielkich próbek. Za pomocą automatycznej analizy wydźwięku i rozwiązań typu big data można monitorować wszystkie kluczowe obszary Internetu.
W przypadku prawie każdego biznesu niezwykle istotna jest analiza danych o sprzedaży --- przewidywanie trendów sprzedażowych, czy segmentacja klientów. Pozwala to na podejmowanie decyzji wpływających na strategię firmy w zakresie oferty produktowej, czy funkcjonowanie działu handlowego.
Niezmiernie ciekawym trendem ostatnich lat jest koncepcja open data: udostępnianie w ustrukturyzowanej formie danych, pochodzących z instytucji publicznych, administracji i innych źródeł istotnych dla obywateli oraz ich późniejsza analiza. Pierwszy krok okazuje się tu często najtrudniejszy i kluczowy, ponieważ przełamywanie barier administracyjnych przypomina walkę z wiatrakami, ale doprowadzenie do udostępnienia danych publicznie daje szansę na to, że każdy z zainteresowanych obywateli może potencjalnie przekształcić uwolnione informacje w realną wartość dla innych. Przykładem może tu być analiza przyczyn i możliwych rozwiązań tworzenia się korków w mieście, na podstawie danych przestrzennych o szybkości poruszania się samochodów na drogach, w poszczególnych godzinach dnia.
Jak zostać Data Scientist?
Jeszcze do niedawna specjaliści dzielili się na tych, którzy zdobyli swoje kompetencje na uczelniach oraz na tych, którzy sami przyuczyli się do zawodu w czasie pracy. Obecnie obserwujemy zupełnie nowe trendy w edukacji, zwracające uwagę na przewagę alternatywnych sposobów zdobywania wiedzy w stosunku do studiów wyższych oraz na konieczność ciągłego aktualizowania swojej wiedzy, przez całe życie (lifelong learning).
Przejawem pierwszego z tych trendów są bootcampy, intensywne kursy skoncentrowane na przekazaniu uczestnikom bardzo praktycznej wiedzy, umożliwiającej im rozpoczęcie pracy w zawodzie, na przykład bootcamp Data Science w Kodołamacz.pl. W drugim przypadku, coraz większą rolę odgrywa obecnie edukacja online, w szczególności kursy typu MOOC (Massive Open Online Courses), które umożliwiają każdemu dostęp do wiedzy na poziomie akademickim zdalnie, za pomocą przeglądarki internetowej.
Tego rodzaju nowatorskie podejścia do edukacji mają oczywiście swoje wady i zalety, w szczególności bootcampy nie są bezpośrednim zamiennikiem kilkuletnich studiów na poziomie magisterskim, czy nawet inżynierskim. Pozwalają szybko zdobyć podstawowe kompetencje praktyczne, tak aby móc rozpocząć pracę i dalej rozwijać swoje umiejętności już w trakcie realizowania codziennych zadań. Kursy online są z kolei znakomitym materiałem do nauki, często na poziomie najlepszych światowych uczelni, nie są jednak w stanie zastąpić bezpośredniego kontaktu z nauczycielem i zapewnić motywacji, jaką daje obecność w fizycznej grupie studentów.


Bootcampy --- czy spełniają swoją rolę?
Dziedzina Data Science jest tu szczególnie problematyczna, ponieważ bazą kompetencji osoby w tej roli są silne podstawy matematyczne i statystyczne. Tego rodzaju wiedza trudna jest do przyswojenia w ciągu kilkutygodniowego kursu. Nie jest to oczywiście wykluczone, ale wymaga jeszcze długiego stażu w miejscu pracy, aby nabrać odpowiedniego doświadczenia. Wydaje się zatem, że klasyczny model edukacji uniwersyteckiej jest tu nadal wiodący.
Uzupełnieniem oferty studiów magisterskich, których program jest często podstawowy i nie pokrywa problematyki specjalistycznej, a także często nie nadąża za szybko zmieniającymi się technologiami, są studia podyplomowe. Na rynku polskim kilka uczelni oferuje studia z zakresu Data Science, w szczególności w tym roku akademickim na Politechnice Warszawskiej otwarte będą dwie ścieżki studiów podyplomowych: Data Science oraz Big Data (disclaimer: Sages i autor zaangażowani są bezpośrednio w organizację wspomnianych studiów podyplomowych i bootcampów Kodołamacz.pl).
Jeśli chcesz rozpocząć karierę w tej branży, koniecznie przeczytaj artykuł Michała Kardasza: Jak znaleźć pierwszą pracę w Data Science?
Niezależnie od posiadanego wykształcenia, kwestia uczenia się przez całe życie jest wyjątkowo istotna w kontekście Data Science, jako że obejmuje swoim zasięgiem najdynamiczniej zmieniające się obszary obecnej rzeczywistości, takie jak technologie programistyczne, czy analiza i przetwarzanie danych. W tym obszarze pomocne są materiały dostępne online (MOOC), kursy i szkolenia, czy członkostwo w tematycznych grupach zainteresowań i meetupach.
Jak budować swoją karierę jako Data Scientist?
Na koniec kilka słów o tym, co można zrobić będąc już specjalistą z zakresu analizy danych, aby wzmocnić swój wizerunek na rynku i rozwijać swoją karierę w przemyślany sposób. Na myśl przychodzi serwis Kaggle, który stał się obecnie nowoczesnym i dynamicznym CV dla Data Scientists, podobnie jak GitHub dla programistów.
Serwis Kaggle to po pierwsze platforma, na której organizowane są konkursy na najlepsze rozwiązania problemów, powiązanych z analizą danych, ogłaszane przez firmy z całego świata. W konkursach startować może każdy, kto na podstawie udostępnionego opisu i przykładowych danych zaproponuje algorytmiczne rozwiązanie danego zagadnienia. W ten sposób buduje swój "życiorys", który jest wizytówką osoby, popartą rzeczywistymi danymi empirycznymi o skuteczności zaproponowanych metod. Z drugiej strony Kaggle jest platformą wyszukiwania najbardziej utalentowanych pracowników: firmy zainteresowane rekrutacją mogą przeszukiwać bazę wspomnianych elektronicznych CV i dobrać osobę o najbardziej odpowiednim profilu.
Podobnie jak programiści, wielu specjalistów z zakresu analizy danych funkcjonuje na portalach typu StackExchange, wspomagając innych odpowiedziami na zadawane pytania. Oprócz tego są oczywiście klasyczne sposoby na dokumentowanie i opisywanie swojej pracy, jak choćby publikacje konferencyjne i w czasopismach naukowych.
Co jeszcze? Dajcie znać w komentarzach.





