



Kreatywność - to z pewnością jedna z najbardziej pożądanych umiejętności w pracy pentestera. Moim zdaniem, popartym praktyką, znajomość Data Science znacznie poszerza analizę potencjalnych zagrożeń, czy słabych punktów.
Postaram się przez najbliższe linijki kodu przedstawić możliwości kryjące się w liczbach używając uczenia maszynowego. Wszystko w duchu rozwiązywania realnych zagadnień, w praktyczny sposób, co oznacza także szczegóły związane z konfiguracją środowiska i wdrażaniem, jako uzupełnienie tworzenia modeli na czystych danych.
Definiowanie problemu
Zbieranie odpowiednich danych jest jednym z poważniejszych problemów inżynierii oprogramowania. Tym razem zajmiemy się danymi neutralnymi, które łatwo można pobrać z oficjalnego źródła, bez potrzeby uzyskiwania pozwolenia lub ograniczeń wynikających z licencji. Warto o tym pamiętać, ponieważ z jednej strony dane są, jest ich n-skończona ilość, ale nie do wszystkich mamy łatwy dostęp. Myślę, że temat rozwiniemy podczas tegorocznych warsztatów w ramach Testaton 2020.
Naszym celem są dane dotyczące zawodników NBA. W teorii proste zadanie, ale okazuje się, że gromadzenie danych obfituje w ciekawe pułapki. Miejscem startowym jest oficjalna witryna nba.com, jednak śladem wielu stowarzyszeń sportowych, liga NBA, także utrudnia dostęp do surowych, nieprzetworzonych danych. Oczywiście zadanie jest wykonalne, ale niełatwe, dlatego pod artykułem zamieściłam link z danymi, tak aby można było skupić się na ich czyszczeniu i analizie, a nie szukaniu.
Skłaniam się ku tezie, iż wielu przypadkach szybszym i najskuteczniejszym wyjściem jest ręczne zbieranie danych, czyli pobieranie ich z witryny, czyszczenie w Exelu lub notatniku Jupyter.
Źródła danych
Praca z danymi wykracza znacząco poza znalezienie odpowiedniego modelu, który pozwoli wstępnie dane wyczyścić i przygotować, pierwszym krokiem zawsze powinno być zrozumienie, jak przygotować swoje środowisko lokalne.
W naszym przypadku będę to dwa kroki:
- Utworzenie środowiska wirtualnego (dla Python 3.6)
- Zainstalowanie niezbędnych pakietów, czyli Pandas i Jupyter
Dlaczego środowisko wirtualne?
Jest ono odseparowane i całkowicie niezależne od głównej instalacji Pythona. Każdy projekt, powinien zawierać swoje środowisko, co pozwala na instalację unikalnych pakietów. Fizycznie jest to nowy katalog na dysku, w którym znajduje się kopia Pythona, po instalacji zawiera jedynie podstawowe pakiety, a my nie zaśmiecamy sobie systemu i mamy do dyspozycji dowolną liczbę takich środowisk, wszystko zależy od naszych wymagań. Rozwiązanie z wirtualnym środowiskiem ułatwia współdzielenie kodu i umieszczanie go w repo, ponieważ zamiast całego folderu ze wszystkimi pakietami, umieścimy tylko jeden z wymaganymi wersjami. Minusem jest oczywiście malejące miejsce na dysku. Czysta instalacja zajmuje na początek około 30 MB, a wraz z każdym nowym pakietem ta liczba wzrasta.
Co to jest Jupyter? Możemy, w bardzo dużym uproszczeniu, określić jako notebook, który pozwala na tworzenie interaktywnych arkuszy mogących zawierać kod wykonywalny, opisy, tabele, wykresy i wiele innych danych, wykorzystywanych między innymi do prezentacji wyników naszej pracy z danymi. Sama instalacja Jupytera wymaga jedynie komendy pip3 install jupyter, a następnie jupyter notebook. Oczywiście warto zainstalować w wirtualnym środowisku, ale o tym pamiętamy.
Biblioteka Pandas?
Jedno z najważniejszych narzędzi wykorzystywanych w pracy Data Science czy też Analytics. Posiada mnóstwo metod służących do wczytywania danych, ich przeglądania, a także sprawdzania np. pod kątem wartości pustych. Warto poznać możliwości Pandasa, bo to praktycznie ‘must have’ w Machine Learningu i wiem, że się powtarzam, ale będziemy o niej mówić podczas warsztatów.
Ciekawym trikiem, pomagającym radzić sobie z wirtualnym środowiskiem Pythona jest utworzenie aliasu w pliku .bashrc lub .zshrc, dzięki takiemu rozwiązaniu środowisko będzie aktywować się automatycznie. Z reguły można użyć:


Pracę z danymi rozpoczynamy od uruchomienia Jupytera, przy użyciu znanego już polecenia jupyter notebook. Spowoduje ono uruchomienie domyślnej przeglądarki i wyświetlenie strony, umożliwiającej przejrzenie istniejących notatników lub utworzenie nowych.
Następnie importujemy zainstalowaną na swoim lokalnym hoście bibliotekę Pandas, podajemy ścieżkę do katalogu z danymi i już… możemy przeglądać.



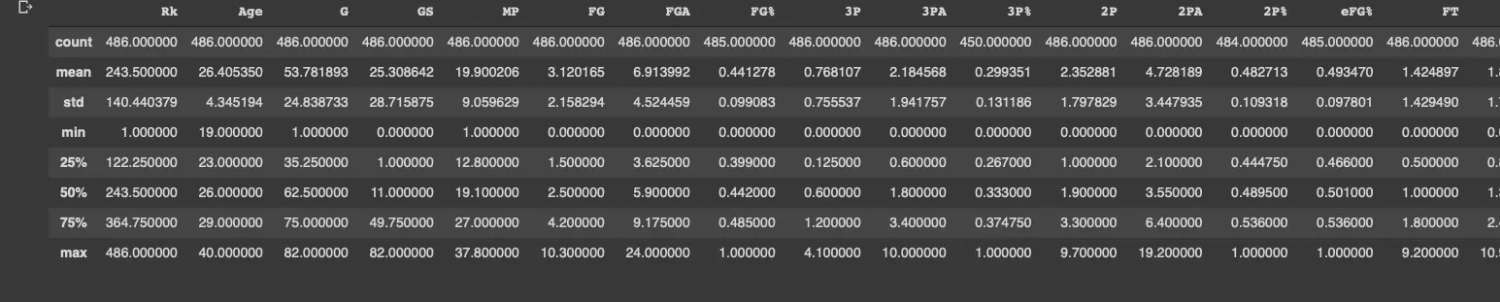
Ładowanie samego pliku CSV do biblioteki Pandas, jest banalne, o ile plik zawiera nazwy kolumn i wiersze każdej są równej długości. W praktyce nigdy tak łatwo nie jest i nadanie danym właściwego kształtu wymaga nakładu pracy i czasu. Polecenie describe z Notebooku udostępnia statystyki opisowe, w tym liczbę kolumn oraz medianę dla każdej z nich. Warto już na tym etapie pamiętać, że analiza danych wymaga ciągłego posuwania się naprzód, bez rozpraszania na zbytnie szczegóły, ponieważ możemy stracić mnóstwo czasu na automatyzowanie sprzątania zbioru danych jedynie po to, by na końcu stwierdzić, że wszystkie wnioski z tego źródła nie były zbytnio pomocne.
W naszym katalogu z danymi mamy ciekawy arkusz dotyczący drużyn. Warto poznać jego zawartość, zaczynamy zatem od importu potrzebnych bibliotek.

W kolejnym kroku tworzymy prosty Dataset (czyli zbiór) dla każdego źródła.

W ten sposób uzyskujemy łańcuch Datasetów, co jest typową praktyką przy gromadzeniu danych z źródeł rozproszonych.

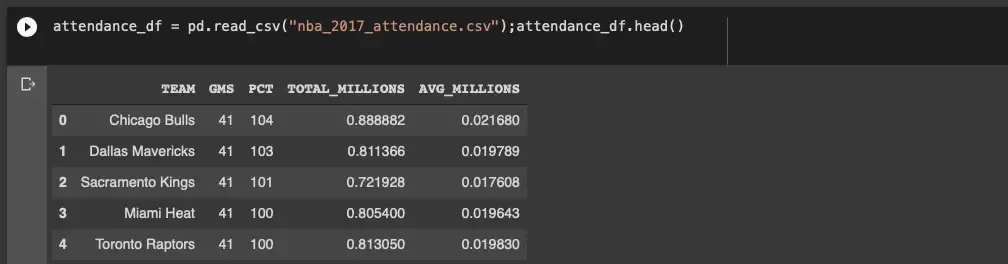
Mamy możliwość łączenia danych frekwencji z danymi wyceny drużyny:
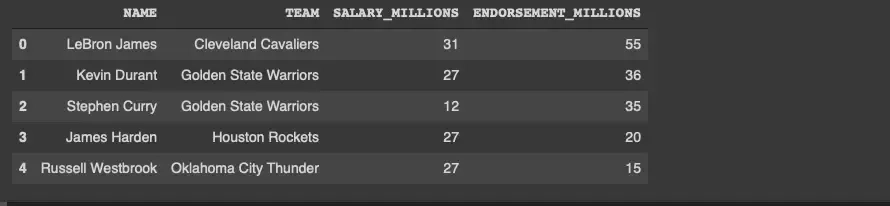
endorsement_df = pd.read_csv("nba_2017_endorsements.csv");endorsement_df.head()

Wykorzystując funkcję pairplot z biblioteki Seaborn, otrzymamy macierz wykresów:



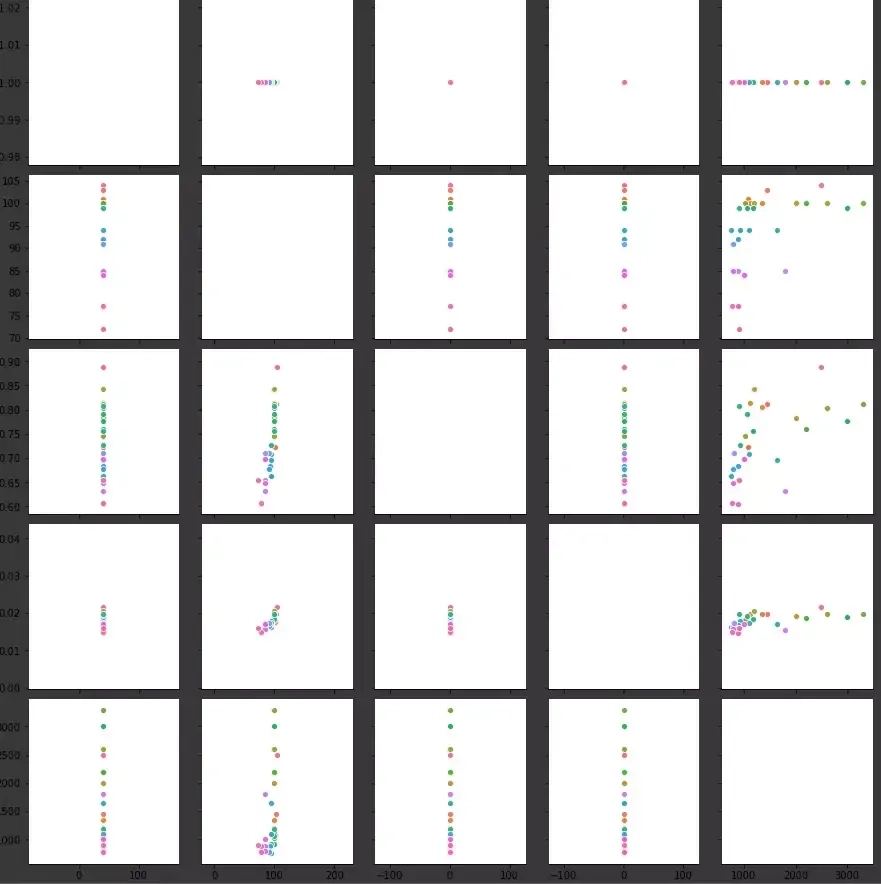
Po wnikliwej analizie można stwierdzić, że istnieje relacja pomiędzy frekwencją, a wartością drużyny, co może nie jest zaskoczeniem, ale warto poświęcić jeszcze trochę czasu i przedstawić relację za pomocą heatmapy korelacji:

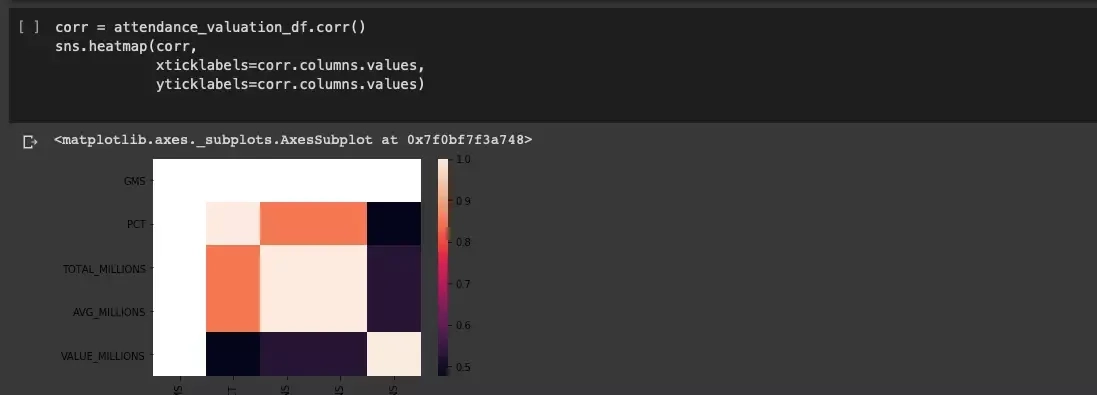
Zależność widoczna w macierzy wykresów jest jeszcze bardziej mierzalna. Analizujemy jeszcze dalej, wykorzystując wykres 3D:

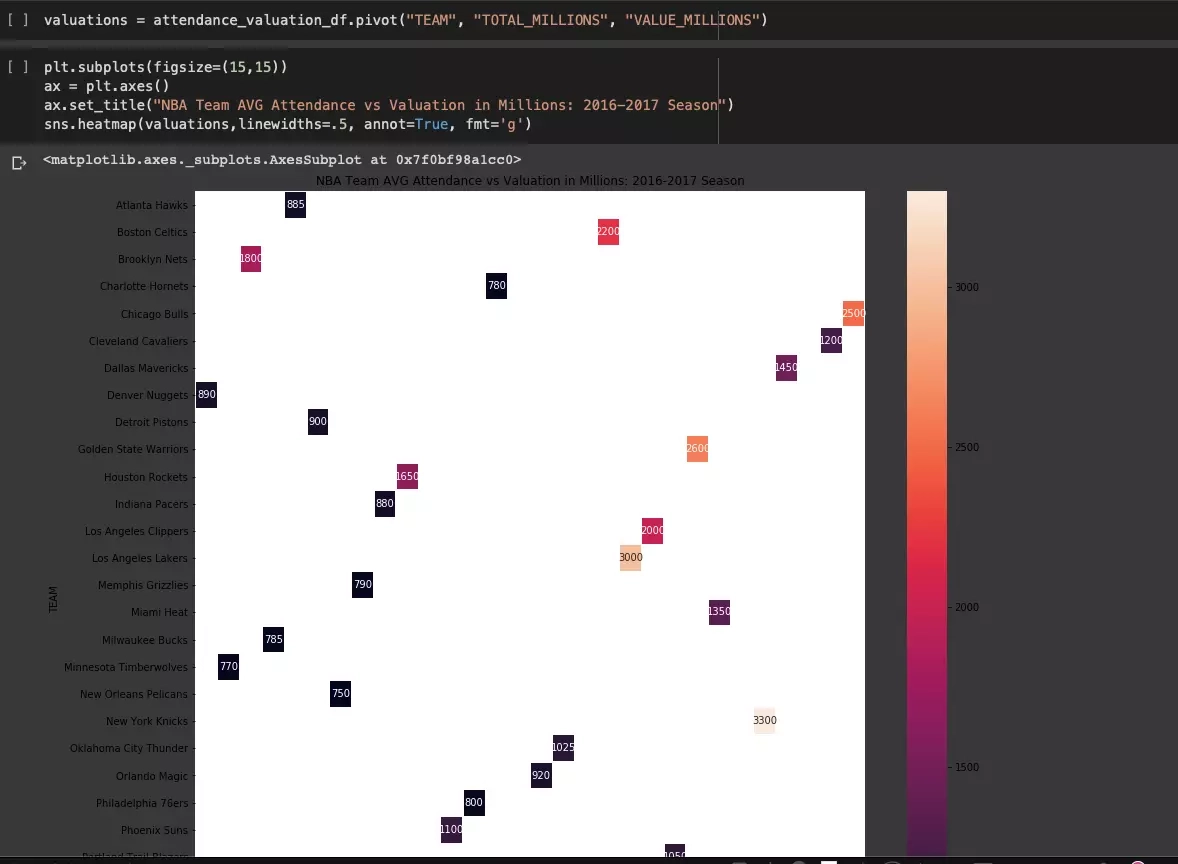
Wykorzystanie regresji podczas eksplorowania danych
Jedną z kolejnych metod badania jest użycie regresji liniowej, co ostatecznie ma ułatwić ocenę zależności. Wykorzystamy pakiet StatsModel, ponieważ chcemy uzyskać wartościowe wyjście diagnostyczne.

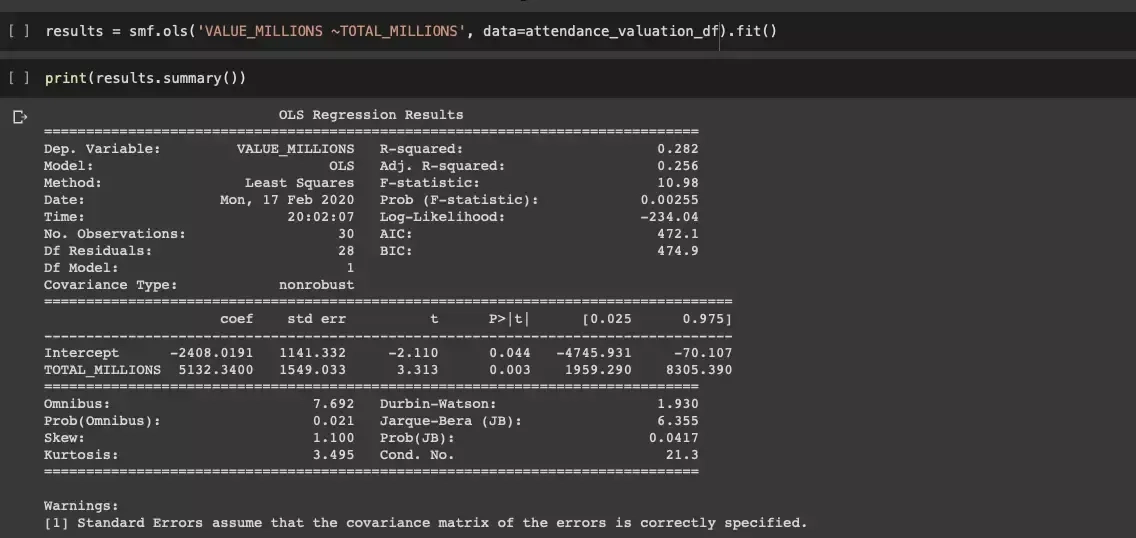
Zmienna TOTAL_MILLIONS, czyli całkowita frekwencja wyrażoną w milionach widzów, jest statystycznie znaczące w prognozowaniu jej zmian.
Wykorzystywany już Seaborn zawiera wbudowaną i ciekawą funkcję residplot, pozwalającą na wykreślenie reszty dla regresji liniowej:

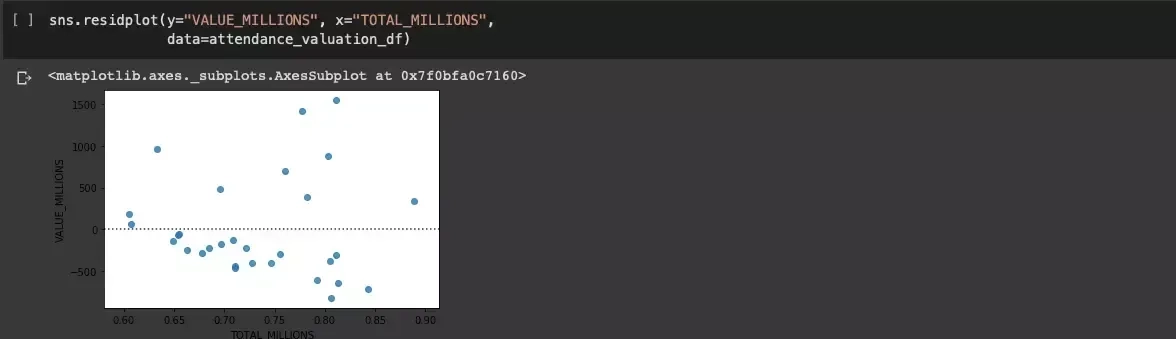
Uzyskujemy potwierdzenie, że wzorzec nie był jednolicie losowy.
Wniosek
Istnieje relacja pomiędzy frekwencją, a wyceną drużyny NBA, lecz pamiętajmy o ukrytych zmiennych, które na tym etapie pozwalają jedynie przypuszczać, że wpływ mogą mieć takie czynniki jak ludność regionu, przeciętne ceny nieruchomości (co jest traktowane jako miara zamożności), a także jak dobra jest dana drużyna (procentowa liczba zwycięstw)
Z takim zestawem danych możemy sięgnąć po bardziej wymagające źródła. W tym miejscu dopiero poznajemy najlepsze i najciekawsze zakątki pracy nie tylko osób zajmujących się Data Science, ale także pentesterów, czy informatyków śledczych.
Gromadzenie danych o wyświetleniach stron Wikipedii dla sportowców
Skupimy się na poniższych wyzwaniach:
- Jak wydobyć w Wikipedii informacje o wyświetlanych stronach?
- Jak znaleźć sposób generowania linków odsyłających do Wikipedii?
W poniższym kodzie zaczynamy od pokazania URL-a do API Wikipedii pozwalajace na wyświetlanie stron oraz moduły:
- Requests wykonuje wywołania HTTP,
- Pandas konwertuje wyniki do Dataframów ,
- Wikipedia wykrywa zależności między URL-ami Wikipedii
Hackerski typ kodu nie jest tutaj przeszkodą, ale oczywiście można napisać go dużo lepiej. Sleep ustawiony na 0 może się okazać problemem, ale tylko wówczas gdy natrafimy na ograniczenia wykorzystywanego API.

Bardziej interesująca wydaje się sekcja kodu związana z linkami i dla naszych potrzeb przyjmuje formę first_last (dotyczy oczywiście imienia i nazwiska zawodnika). Raczej tak prosto nie będzie w innych przykładach, ale warto spróbować.

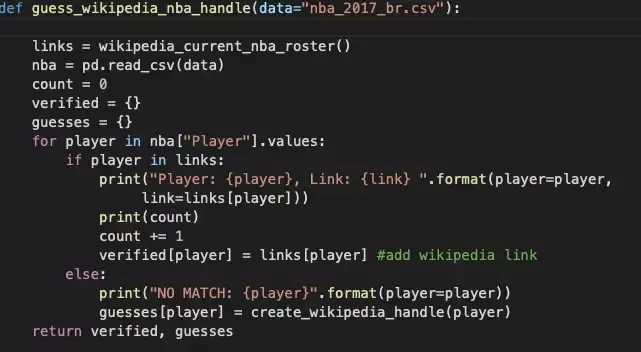
Ostatecznie konstruujemy URL, zawierający zakres danych na temat zawodnika.

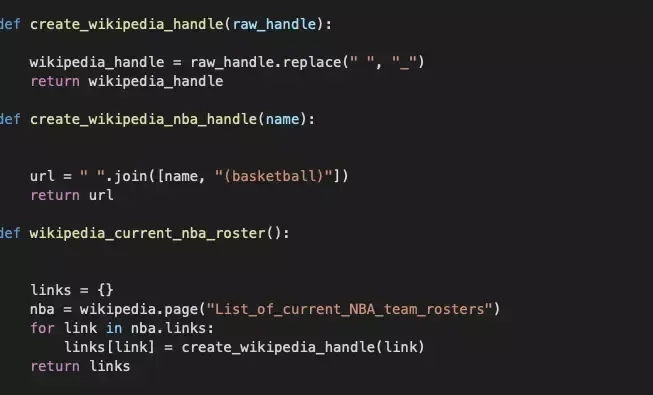
Używając biblioteki wikipedia możemy przekonwertować wyniki wyszukiwania dla first_last.

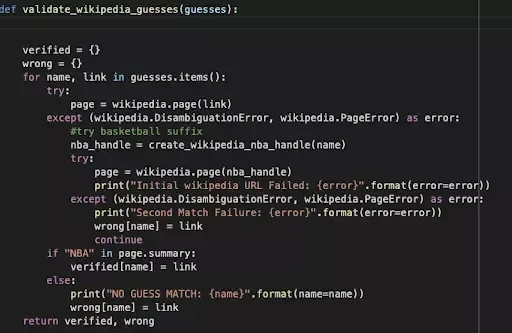
Wykonanie analizy, a przede wszystkim prób wydobycia najbardziej wartościowych dla nas informacji może zająć dowolną ilość czasu :) Wszystko zależy od źródeł, dostępności danych, naszej praktyki. Powyższy przykład pokazał realizm “walki” z różnymi źródłami danych, wszystko po to, aby rozwiązać pierwotnie określony cel.
Przykład z danymi NBA miał na celu wykazanie,, że kilka dosyć przyjaznych bibliotek Pythona pozwala na bardzo ciekawą analizę dowolnych danych, szukanie interesujących zależności, a tym samym lokalizację kolejnych punktów zaczepienia, stanowiących świetnym początkiem dla przygotowania środowiska dla pentestów lub, co warto zauważyć, pomaga ocenić wagę informacji zawartych w źle zabezpieczonych dokumentach, a tutaj nie trzeba już wspominać o niezwykłej wartości dodanej w raporcie końcowym.





